| Firebird Documentation Index → Firebird 2.0.6 Release Notes → Enhancements to Indexing → Firebird Index Structure from ODS11 Onward |
|
The aims achieved by the new structure were:
better support for deleting an index-key out of many duplicates (caused slow garbage collection)
support for bigger record numbers than 32-bits (40 bits)
to increase index-key size (1/4 page-size)
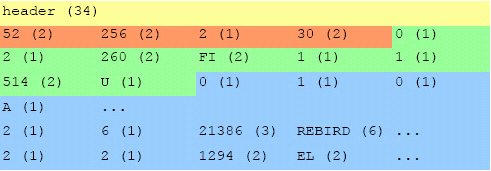
header =
typedef struct btr {
struct pag btr_header;
SLONG btr_sibling; // right sibling page
SLONG btr_left_sibling; // left sibling page
SLONG btr_prefix_total; // sum of all prefixes on page
USHORT btr_relation; // relation id for consistency
USHORT btr_length; // length of data in bucket
UCHAR btr_id; // index id for consistency
UCHAR btr_level; // index level (0 = leaf)
struct btn btr_nodes[1];
};
node =
struct btn {
UCHAR btn_prefix; // size of compressed prefix
UCHAR btn_length; // length of data in node
UCHAR btn_number[4]; // page or record number
UCHAR btn_data[1];
};
end marker = END_BUCKET or END_LEVEL
These are in place of record-number for leaf nodes and in place of page-number for non-leaf nodes.
If the node is a END_BUCKET marker then it should contain the same data as the first node on the next sibling page.
On an END_LEVEL marker prefix and length are zero, thus it contains no data. Also, every first node on a level (except leaf pages) contains a degeneration zero-length node.
jump info =
struct IndexJumpInfo {
USHORT firstNodeOffset; // offset to first node in page [*]
USHORT jumpAreaSize; // size area before a new jumpnode is made
UCHAR jumpers; // nr of jump-nodes in page, with a maximum of 255
};
jump node =
struct IndexJumpNode {
UCHAR* nodePointer; // pointer to where this node can be read from the page
USHORT prefix; // length of prefix against previous jump node
USHORT length; // length of data in jump node (together with prefix this
// is prefix for pointing node)
USHORT offset; // offset to node in page
UCHAR* data; // Data can be read from here
};
New flags are added to the
header->pag_flags.
The flag btr_large_keys (32) is for storing
compressed length/prefix and record-number. This meant also that length
and prefix can be up to 1/4 of page-size (1024 for 4096 page-size) and
is easy extensible in the future without changing disk-structure
again.
Also the record-number can be easy extended to for example 40 bits. Those numbers are stored per 7-bits with 1 bit (highest) as marker (variable length encoding). Every new byte that needs to be stored is shifted by 7.
Examples
25 is stored as 1 byte 0x19, 130 = 2 bytes 0x82 0x01, 65535 = 3 bytes 0xFF 0xFF 0x03.
A new flag is also added for storing record-number on every node
(non-leaf pages). This speeds up index-retrieval on many duplicates. The
flag is btr_all_recordnumber (16).
With this added information, key-lookup on inserts/deletes with many duplicates (NULLs in foreign keys, for example) becomes much faster (such as the garbage collection!).
Beside that duplicate nodes (length = 0) don't store their length information, 3 bits from the first stored byte are used to determine if this nodes is a duplicate.
Beside the ZERO_LENGTH (4) there is also END_LEVEL (1), END_BUCKET (2), ZERO_PREFIX_ZERO_LENGTH (3) and ONE_LENGTH (5) marker. Number 6 and 7 are reserved for future use.
A jump node is a reference to a node somewhere in the page.
It contains offset information about the specific node and the prefix data from the referenced node, but prefix compression is also done on the jump-nodes themselves.
Ideally a new jump node is generated after the first node that is
found after every jumpAreaSize, but that's only the
case on deactivate/active an index or inserting nodes in the same order
as they will be stored in the index.
If nodes are inserted between two jump node references only the offsets are updated, but only if the offsets don't exceed a specific threshold (+/-10 %).
When a node is deleted only offsets are updated or a jump node is removed. This means a little hole can exist between the last jump node and the first node, so we don't waste time on generating new jump-nodes.
The prefix and length are also stored by variable length encoding.
Pointer after fixed header = 0x22
Pointer after jump info = 0x29
Pointer to first jump node = 0x29 + 6 (jump node 1) + 5 (jump node 2) = 0x34
Jump node 1 is referencing to the node that represents FIREBIRD as data, because this node has a prefix of 2 the first 2 characters FI are stored also on the jump node.
Our next jump node points to a node that represents FUEL with also a prefix of 2. Thus jump node 2 should contain FU, but our previous node already contained the F so, due to prefix compression, this one is ignored and only U is stored.
The data that needs to be stored is determined in the procedure compress() in btr.cpp.
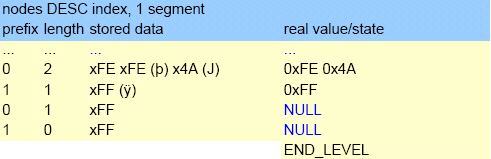
For ASC (ascending) indexes no data will be stored (key is zero length). This will automatically put them as first entry in the index and thus correct order (For single field index node length and prefix is zero).
DESC (descending) indexes will store a single byte with the value 0xFF (255). To distinguish between a value (empty string can be 255) and an NULL state we insert a byte of 0xFE (254) at the front of the data. This is only done for values that begin with 0xFF (255) or 0xFE (254), so we keep the right order.
 |
 |
 |
| Firebird Documentation Index → Firebird 2.0.6 Release Notes → Enhancements to Indexing → Firebird Index Structure from ODS11 Onward |